....by the way, this is very cool: https://github.com/eclipse/openj9/issues/5058
RISC-V is basically a serious attempt at Open Source hardware: https://www.google.com/search?q=risc-v
Wednesday, March 13, 2019
Latency matters
This is simple and perhaps even obvious, but if you're simulating a fast strategy on high-resolution historical data – you at least need to simulate some average latency or the results are probably misleading.
For some exchanges, you also need to look out for weird(?) looking bulks of orders and/or order book updates that all have the exact same timestamp(!). Figuring out what actually happened here is tricky or even impossible and everything but limit orders will, I think, just be guesswork. It seems reasonable to assume that none of your order adds or updates went through during a period like this – and latency is probably higher than average just before and afterwards.
This result is only possible with 0 latency:

..the moment I add a little latency to this simulation, the diagonal blue line (PnL) is flipped!
For some exchanges, you also need to look out for weird(?) looking bulks of orders and/or order book updates that all have the exact same timestamp(!). Figuring out what actually happened here is tricky or even impossible and everything but limit orders will, I think, just be guesswork. It seems reasonable to assume that none of your order adds or updates went through during a period like this – and latency is probably higher than average just before and afterwards.
This result is only possible with 0 latency:
..the moment I add a little latency to this simulation, the diagonal blue line (PnL) is flipped!
Friday, March 8, 2019
Clojure quick performance tip: fastest(?) vector concatenation
I don't like CONCAT or MAPCAT; they create intermediate lazy seqs and have some potential problems if you're not careful. I use this instead:
..for me this yields about a 50% performance improvement compared to the perhaps more typical (vec (mapcat ..)) pattern. The key here is the use of a single transient for the entire process and no creation or use of intermediate values.
NOTE: The simplest case i.e. concatenating two vectors together is of course just (into [0 1] [2 3]) => [0 1 2 3] ..which uses transients internally.
I was testing rrb-vector for a while, but it seems to have some serious bugs..
(defn catvec
([s] (catvec [] s))
([init s]
(persistent! (reduce #(reduce conj! %1 %2)
(transient init)
s))))
> (catvec [[1 2] nil [3 4 5] [6] [] [7 8]])
[1 2 3 4 5 6 7 8]
> (catvec [0] [[1 2] nil [3 4 5] [6] [] [7 8]])
[0 1 2 3 4 5 6 7 8]
..for me this yields about a 50% performance improvement compared to the perhaps more typical (vec (mapcat ..)) pattern. The key here is the use of a single transient for the entire process and no creation or use of intermediate values.
NOTE: The simplest case i.e. concatenating two vectors together is of course just (into [0 1] [2 3]) => [0 1 2 3] ..which uses transients internally.
I was testing rrb-vector for a while, but it seems to have some serious bugs..
Saturday, February 16, 2019
Will the real Kelly please stand up?
Quick post this one; most of you probably already know about the Kelly criterion: https://en.wikipedia.org/wiki/Kelly_criterion
...well, make sure you check this out: https://blogs.cfainstitute.org/investor/2018/06/14/the-kelly-criterion-you-dont-know-the-half-of-it/ ...because you might be using the "wrong Kelly"!
Here's how the correct one looks like in Clojure with primitive type hints so the compiler will generate proper code suited for your CPU; really, really simple:
(defn kelly-criterion% ^double [^double win-chance ^double avg-winner ^double avg-loser]
(- (/ win-chance avg-loser)
(/ (- 1.0 win-chance) avg-winner)))
I had to "choke" this or it would in some cases generate very high leverage trades on my backtest. I tried basing the kelly% on a 14 day window so it will be more reactive based on the current market state -- and this was the result for a very simple momentum trader (edit: i'll try posting the original later; so you can see a before vs. after):
..for me this represents a big improvement; even for a trivial strategy.
update: here's the same strat without any kelly% =>
...well, make sure you check this out: https://blogs.cfainstitute.org/investor/2018/06/14/the-kelly-criterion-you-dont-know-the-half-of-it/ ...because you might be using the "wrong Kelly"!
Here's how the correct one looks like in Clojure with primitive type hints so the compiler will generate proper code suited for your CPU; really, really simple:
(defn kelly-criterion% ^double [^double win-chance ^double avg-winner ^double avg-loser]
(- (/ win-chance avg-loser)
(/ (- 1.0 win-chance) avg-winner)))
I had to "choke" this or it would in some cases generate very high leverage trades on my backtest. I tried basing the kelly% on a 14 day window so it will be more reactive based on the current market state -- and this was the result for a very simple momentum trader (edit: i'll try posting the original later; so you can see a before vs. after):
 | |
| XBTUSD (futures). When kelly% goes negative we do not trade -- and we are more aggressive (leverage) when confidence is higher. Depending on your stomach, the amount of leverage could probably be throttled a bit further than what I've done here. |
..for me this represents a big improvement; even for a trivial strategy.
update: here's the same strat without any kelly% =>
 |
| No kelly%; just fixed order size. This trades even when the strategy performs poorly and one can perhaps argue that it not aggressive enough when the strategy is doing well. |
Friday, February 8, 2019
SVG for plots ....cool, or?
So I tried this: https://quanto.ga/qa/plot_svg_viewer.html?plot_url=/8thfebplot.svg ..use mousewheel to zoom/in out and drag-and-drop to pan.
If I add raw data (millions of data points) the browsers and viewers I've tried can't handle it. :(
{kind=link}
If I add raw data (millions of data points) the browsers and viewers I've tried can't handle it. :(
Sunday, January 20, 2019
Quick backtest update [ STRATEGY-TREND-1: XBTUSD @ 2018-11-01 -> 2019-01-17 ]
STRATEGY-TREND-1: XBTUSD @ 2018-11-01 -> 2019-01-17 { git: a623d60742e96d35b8f7365496ffd99911aa7dbb }
NOTE: I'll post future backtests on this page ==> https://quantoga.blogspot.com/p/backtests.html
- 10000 USD fixed position size (perpetual futures contracts).
- Fees are included.
- Limit orders are used for both entries and exits.
Huge improvements are still possible; i.e. even by adding basic kelly% for position sizing+++.
NOTE: the candle coloring isn't a very good representation of what's going on. The color is only based on avg position at a single point in time (the open). The candle at 2019-01-10 (2nd image) is shown as a long (green), but that's only for the first part of the candle before it goes short. It then goes long again before the next candle -- which is therefore green "again". In the end the initial loss for that duration is cancelled out by the gain from the brief short taken in the middle of the drop.

 |
| Don't pay too much attention to the colors in this; they are not correct or accurate. |
...this is based on recent improvements to the strategy I did a screencapture of here: https://www.youtube.com/watch?v=JnCQ3qOKou4 ..actually, the biggest change is probably a move from trading based on discrete time to continuous time and the addition of a signal system with dedicated grace durations etc. etc..
Tuesday, January 15, 2019
Clojure for fast processing of streams of data via LAZY-SEQ and SEQUE
UPDATE: After some back and forth I think clojure.core.async with its several buffers both at source, computation/transformation and sink areas is a better fit for what I'm doing!
LAZY-SEQ and SEQUE are useful in many contexts where you need to speed up processing of streams of data (SEQ) from e.g. another computation, a filesystem or a web or database server -- anything really.
The key idea is that SEQUE will continuously fetch the next n few elements from the stream in advance and in the background (thread) -- while the code that consumes or handles the data keeps on working on the current or already fetched element(s) in the foreground.
A quick video to demonstrate the effect:
SEQUE uses a LinkedBlockingQueue behind the scenes, but you can pass it anything that implements the BlockingQueue interface as needed.
Clojure makes this simple and fun and all of this might be pretty basic and trivial for many, but a small "trick" is needed to set it up correctly -- like this:
Thursday, January 10, 2019
Big data: from compressed text (e.g. CSV) to compressed binary format -- or why Nippy (Clojure) and java.io.DataOutputStream are awesome
Say you have massive amounts of historical market data in a common, gzip'ed CSV format or similar and you have these data types which represents instances of the data in your system:
(defrecord OFlow ;; Order flow; true trade and volume data!
[^double trade ;; Positive = buy, negative = sell.
^double price ;; Average fill price.
^Keyword tick-direction ;; :plus | :zero-plus | :minus | :zero-minus
^long timestamp ;; We assume this is the ts for when the order executed in full.
^IMarketEvent memeta]
(defrecord MEMeta
[^Keyword exchange-id
^String symbol
^long local-timestamp])
A good way to store and access this would be to use a binary format and a modern, fast compression algorithm. The key issue is fast decompression and LZ4HC is the best here as far as I'm aware of -- apparently reaching the limitations of what's possible with regards to RAM speed. To do this we'll use https://github.com/ptaoussanis/nippy which exposes the DataOutputStream class nicely and enables us to express a simple binary protocol for reading and writing our data types, like this:
(nippy/extend-freeze OFlow :QA/OFlow [^OFlow oflow output]
(.writeDouble output (.trade oflow))
(.writeDouble output (.price oflow))
(.writeByte output (case (.tick-direction oflow)
:plus 0, :zero-plus 1, :minus 2, :zero-minus 3))
(.writeLong output (.timestamp oflow))
;; MEMeta
(.writeUTF output (name (.exchange-id ^MEMeta (.memeta oflow))))
(.writeUTF output (.symbol ^MEMeta (.memeta oflow)))
(.writeLong output (.local-timestamp ^MEMeta (.memeta oflow))))
(nippy/extend-thaw :QA/OFlow [input]
(->OFlow (.readDouble input)
(.readDouble input)
(case (.readByte input)
0 :plus, 1 :zero-plus, 2 :minus, 3 :zero-minus)
(.readLong input)
(->MEMeta (keyword (.readUTF input))
(.readUTF input)
(.readLong input))))
..to write out the binary data to a file, you'd do something like (oflow-vector is a vector containing OFlow instances):
(nippy/freeze-to-file "data.dat" oflow-vector
{:compressor nippy/lz4hc-compressor, :encryptor nil, :no-header? true})
..and to read it back in to get a vector of OFlow instances as the result you'd do something like this:
(nippy/thaw-from-file "data.dat"
{:compressor nippy/lz4hc-compressor, :encryptor nil, :no-header? true})
...it's so simple and the result is very, very good in terms of speed and space savings [I'll add some numbers here later]. Of course you'd still want to use something like PostgreSQL for indexed views or access to the data, but this is very nice for fast access to massive amounts of sequential, high resolution data. I've split things up in such a way that each file contains 1 day worth of data; this way it is possible to make fast requests to ranges of the data at any location without doing long, linear searches. 👍
Sunday, December 23, 2018
Clojure quick tip: efficiently find last element in vector satisfying some condition
Wednesday, December 12, 2018
A list of #mistakes update: you cannot process events in simple sequential order during live trading
NOTE: I'll keep adding more updates like this under the #mistakes label.
This might be pretty trivial and even obvious, but I keep having to remind myself of this as I "rediscover" it in several somewhat similar situations.
During backtesting you can pretend that you always get events one by one in perfect order and process them in sequence as such because you are in control of time here -- but during live trading you will sometimes get a bulk of events in one go and your strategy, order or event handling code will probably need to be aware of this in order to make good decisions.
E.g.:
As I learn more and more about "stream processing", the more multiple full passes of bulks of data seem to make sense. Sequential processing is an oversimplified view of reality --- it is still useful during simulations though.
This might be pretty trivial and even obvious, but I keep having to remind myself of this as I "rediscover" it in several somewhat similar situations.
During backtesting you can pretend that you always get events one by one in perfect order and process them in sequence as such because you are in control of time here -- but during live trading you will sometimes get a bulk of events in one go and your strategy, order or event handling code will probably need to be aware of this in order to make good decisions.
E.g.:
- You are passed a bulk of events.
- An earlier event in the bulk informs you about an order update (e.g. partial fill) which you generate a response to.
- A later event in the bulk informs you that the position related to that order was closed for whatever reason.
- ...based on §3 your response in §2 might not make sense anymore.
You might think that this will not be a problem for you because your system will be fast enough to handle the events before they queue up anyway -- but this is not only about your system, but also about network and exchange/broker lag. I.e. you are not in control of time here!
As I learn more and more about "stream processing", the more multiple full passes of bulks of data seem to make sense. Sequential processing is an oversimplified view of reality --- it is still useful during simulations though.
Tuesday, November 13, 2018
PostgreSQL: creating OHLC or "candlestick" output from quote/tick raw material
As a quick note to self:
(jdbc/with-db-connection [conn -db-conn-]
(let [t (time.coerce/from-string "2018-02-01")]
(time
(dotimes [i 50]
(let [ts-start (time/plus t (time/hours i))
ts-end (time/plus t (time/hours (inc i)))]
(time (println {:data (jdbc/query conn ["SELECT
first_value(bid_price) OVER w AS first_bid_price,
first_value(ask_price) OVER w AS first_ask_price,
MAX(bid_price) OVER w AS max_bid_price,
MAX(ask_price) OVER w AS max_ask_price,
MIN(bid_price) OVER w AS min_bid_price,
MIN(ask_price) OVER w AS min_ask_price,
last_value(bid_price) OVER w AS last_bid_price,
last_value(ask_price) OVER w AS last_ask_price
FROM bitmex_quote
WHERE timestamp >= ? AND timestamp < ? AND symbol = 'XBTUSD'
WINDOW w AS (ORDER BY timestamp ASC ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING)
ORDER BY timestamp ASC
LIMIT 1;"
(time.coerce/to-sql-time ts-start) (time.coerce/to-sql-time ts-end)])
:timestamp (str ts-end)})))))))
...for this to perform reasonably you'll need to do indexing.
(jdbc/with-db-connection [conn -db-conn-]
(let [t (time.coerce/from-string "2018-02-01")]
(time
(dotimes [i 50]
(let [ts-start (time/plus t (time/hours i))
ts-end (time/plus t (time/hours (inc i)))]
(time (println {:data (jdbc/query conn ["SELECT
first_value(bid_price) OVER w AS first_bid_price,
first_value(ask_price) OVER w AS first_ask_price,
MAX(bid_price) OVER w AS max_bid_price,
MAX(ask_price) OVER w AS max_ask_price,
MIN(bid_price) OVER w AS min_bid_price,
MIN(ask_price) OVER w AS min_ask_price,
last_value(bid_price) OVER w AS last_bid_price,
last_value(ask_price) OVER w AS last_ask_price
FROM bitmex_quote
WHERE timestamp >= ? AND timestamp < ? AND symbol = 'XBTUSD'
WINDOW w AS (ORDER BY timestamp ASC ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING)
ORDER BY timestamp ASC
LIMIT 1;"
(time.coerce/to-sql-time ts-start) (time.coerce/to-sql-time ts-end)])
:timestamp (str ts-end)})))))))
...for this to perform reasonably you'll need to do indexing.
Monday, November 12, 2018
Notes on database stuff: PostgreSQL indexing performance
It might be a very good idea to take a look at e.g. https://www.timescale.com/
Total number of rows (quote data only): 749 640 222
Querying for a single 1 hour "candle" (sort of..) without index: 5 minutes. In other words; completely useless.
..doing the same with index: around 200ms or 1500% (15x) faster. UPDATE: I fiddled around and ended up with these numbers: https://gist.github.com/lnostdal/9e7e710290cd7448cd81b29fc744fbc7 ..this should be faster than my backtester at the moment; at least for non-trivial stuff.
The query I used to test this:
SELECT MAX(bid_price) AS max_bid_price, MIN(bid_price) AS min_bid_price, MAX(ask_price) AS max_ask_price, MIN(ask_price) AS min_ask_price
FROM bitmex_quote
WHERE timestamp >= '2018-07-30 00:00:00' AND timestamp < '2018-07-30 01:00:00' AND symbol = 'XBTUSD';
I'm sure there are ways of organizing and indexing this kind of data which are better and faster than what I've done, but this is an OK start for now.
Building a partial index takes about 30 minutes for each `symbol`. I'm sure all of this would be much faster on proper hardware and finalized configuration of everything; the point are the nice % speedups.
Here's how I built the index:
CREATE INDEX idx_timestamp_xbtusd
ON public.bitmex_quote
USING btree
("timestamp" ASC NULLS LAST)
TABLESPACE pg_default
WHERE symbol = 'XBTUSD';
I create one index like this for each `symbol`. These are partial indexes which I think makes sense for this.
https://www.postgresql.org/docs/11/rules-materializedviews.html is probably a nice way to build very fast viewports of the most common timeframes; 1min, 3min, 5min, 15min, 30min, 1h, 2h and so on.
Friday, November 2, 2018
Notes on Clojure: memory leaks, performance and more
work in progress; i'll add more to this later
Memory leaks
- https://www.eclipse.org/mat/ is great and works with Clojure.
- When debugging, setting -Dclojure.compiler.disable-locals-clearing=true can be nice, but make sure you set this back to false (the default) because it can (will?) create memory leaks in non-trivial code.
- In some cases you should use eduction instead of sequence when dealing with transducers and huge amounts of data.
- Not related to Clojure, but Emacs actually has some leak problems lately: https://debbugs.gnu.org/cgi/bugreport.cgi?bug=26952 so make sure you run a recent Emacs. This is not a problem that bit me often though.
 |
| Spent the last 2 days debugging memory. Turns out 90% of the problem was a wrong JVM flag (#1 above) -- and the remaining 10% of the problem was an issue with clojure.core.async which I'll try to document later. |
Performance
- -Dclojure.compiler.direct-linking=true leads to massive performance improvements in some cases. You'll need to change how you do interactive development after setting this flag tho. I also find return value type hints work better when this is true -- which can help with debugging.
- Make sure you set *warn-on-reflection* to true and *unchecked-math* to :warn-on-boxed. Dealing with this correctly will probably give you the biggest performance of everything else mentioned here.
- It is very important to not use Fns like FIRST on ArrayLists, ArrayDeques and similar. As it will actually generate a temporary object via an internal call to SEQ on every invocation(!). This might be obvious, but it's easy to forget because a simple call to FIRST seems like something that "should" be cheap to do. Stick with the JVM specific methods and interfaces for these classes; get, peekFirst, peekLast etc..
- Also, Vector implements IFn which means you can do (my-vector 0) instead of (first my-vector) for a 4-5x win.
- Always use PEEK instead of LAST when you can.
- This looks useful: https://github.com/clojure-goes-fast
Monday, August 20, 2018
Creating a trading system: list of mistakes
I'll publish further updates in separate posts under the #mistakes label.
I'll add to this list as I remember and/or encounter things:
- Not using enough data for backtesting -- and using the data wrong. I.e. overfitting. This is probably the nr. 1 mistake -- and it's not a binary thing either; you have to determine "how overfit is my strategy? probably?" and yes assuming it is always somewhat overfit is the correct way to view this.
- Thinking 1min data would be "good enough". It's not unless you explicitly architecture your strategies and backtester around certain limitations. You really need tick data for many strategies or else you end up with a lot of uncertainties as to what happened first when things are hectic (and important); e.g. fill vs. stop-loss vs. take-profit.
- Not basing the system around continuous time series data/events.
- Using Joda time instead of primitive longs for timestamps. If I need to deal with messy time calculations I'll coerce the long to a Joda time object then back again.
- Thinking this would be a 6 month project. I've been doing this on and off since 2015(!). This is the 3rd variant or iteration of the project.
- Using mutable state. Yes, I did this even in Clojure for "performance reasons". Of course mutable state in Clojure is fine if you do it in isolated areas -- but I did not do this. Even if I was using something like C++ or Rust I'd be doing functional programming and stick with immutable, persistent data structures at this point.
- It's important to keep the call stack shallow. If one consider handling of exchange related events:
- Have your main loop call the core and basic handling Fn first.
- Then have the same loop (call site) pass the event to your strategy Fn which can further handle the event in more custom ways if needed.
- By keeping the call stack shallow like this your dispatching will be trivial and faster (important if your main-loop does backtesting in addition to live trading) -- and it'll also be easier to eyeball what and where things went wrong via stack traces.
- Avoid overuse of core.async. I'd only use this tool as a stream library I think; not for the "green thread" type stuff. I.e. avoid async/go.
I'll publish further updates in separate posts under the #mistakes label.
Thursday, June 7, 2018
Clojure map concurrency test: MAP vs. PMAP vs. UPMAP
Code:
That's a 96% (!) improvement – if I'm not mistaken. I made a quick video about this here:
That's a 96% (!) improvement – if I'm not mistaken. I made a quick video about this here:
clojure.core.async: how to deal with deadlocks
Perhaps I should post some code snippets and tips on this blog? Much of this will probably be obvious and simple, but it's stuff I sometimes forget.
clojure.core.async: how to deal with deadlocks:
clojure.core.async: how to deal with deadlocks:
Sunday, April 22, 2018
Roadmap: 2018
Last update: June 4rd 2018
Most recently being worked on first:- Get rid of mutable state. General cleanup. Add better support for continuous time series data and overall model the system more around this instead of a strict assumption that everything is or should be (converted to) discrete time series data.
- More testing! Flesh out the rest of the old exchange API components – and do some testing on new exchanges also.
- Deal with trading system vs. exchange sync problems; see text at top of strategy_result_handler.clj. Test using demo account; try to trigger sync problems this time.
- Some "strategy helper" component is need that will deal with :post-only orders that are cancelled because they'd get instantly executed as market orders. Some retry logic with a limit as to how far it will stretch itself would be nice here.
- Architecture backtester in such a way that it's "just another exchange backend". This should make the code and general architecture simpler and more robust. It'll also enable us to have several backtester types.
- While I do handle order book streams, I do not store the historical data here in a DB; fix this.
Roadmap: finished
Most recently finished first:
- Flesh out IExchange which will be used by the strategies to set proper order size and deal with exchanges that do not have dedicated TP / SL fields for their order / position objects. I.e. use a bidir map between entry order <--> tp/sl order. Separate this from exchanges that supports :linked-order-cancellation.
- Handle the output generated by the backtester and strategies and prepare the result for efficient transmission to exchanges. Test using demo account; use fixed values for order size.
- Unify the various market data type streams behind a common interface / protocol and update the code to not assume e.g. OHLC in so many places. Video update here.

27th april

30th april

1st may
- Write some dummy test strategies to verify that the new backtester, trade planner and so on works (it does).
- Add "trade planner"; wraps a base strategy expressed in high-level terms (indicator levels, signals, ++) and uses it to generate future limit entries and limit/stop-loss/take-profit -exits instead of trading using simple reactions (e.g. market orders) in the passing moment. TLDR: this makes it possible to build market making strategies.
- Add support for order flow streams and analysis.
- Refactor the old backtester; split it into smaller components (flexibility).
- Add support for real order- and position objects instead of simple signals.
Future
- If needed check things like http://github.com/vigna/fastutil, https://github.com/eclipse/eclipse-collections (open sourced by Goldman Sachs), ++.
- Take a closer look at Clojure reducers (fold). I did try this before, but ended up blowing up my stack for complex stuff.
- $ grep "TODO" *.clj | wc -l ==> 297
Wednesday, February 7, 2018
2018: Working on new market making strategy; trading the Bitcoin bottom

....very much work in progress scratched down using pinescript. Basically mean reversion with pyramiding. Because of fees and execution latency this strategy will most likely only work well in the real world with limit orders for entries and exits – i.e. the strategy must plan ahead instead of reacting using market orders and/or stop-entries.
It seems to work well on traditional markets too.; natural gas:

....or things like forex; here AUDUSD:

...or more unusual pairs like AUDNZD:

..and stocks, like FB:

Thursday, May 11, 2017
$BTCUSD $BITCOIN: May 2017

Bitcoin (D) has had an amazing run within this channel since finding its bottom during 2015 sideways – and given what happened way back in 2013 it can actually break up from this channel and go parabolic once again. I would not open a new long term long and walk away from it here though.

If you're in a long term long I'd take off half or 1/3 right now or pretty soon and see. Taking any new longer term position (long or short) right now seems like a gamble.
Tuesday, March 14, 2017
Position size & equity curves: linear vs. logarithmic scale
Here’s a short story (from this Wikipedia page) showing why getting position size right is very important:
In one study, each participant was given $25 and asked to bet on a coin that would land heads 60% of the time. The prizes were capped at $250. "Remarkably, 28% of the participants went bust, and the average payout was just $91. Only 21% of the participants reached the maximum. 18 of the 61 participants bet everything on one toss, while two-thirds gambled on tails at some stage in the experiment. Neither approach is in the least bit optimal." Using the Kelly criterion and based on the odds in the experiment, the right approach would be to bet 20% of the pot on each throw. If losing, the size of the bet gets cut; if winning, the stake increases.
Anyway, after developing a new strategy, optimizing it then finally running something like Kelly% on it you might end up with an equity curve that looks like this:
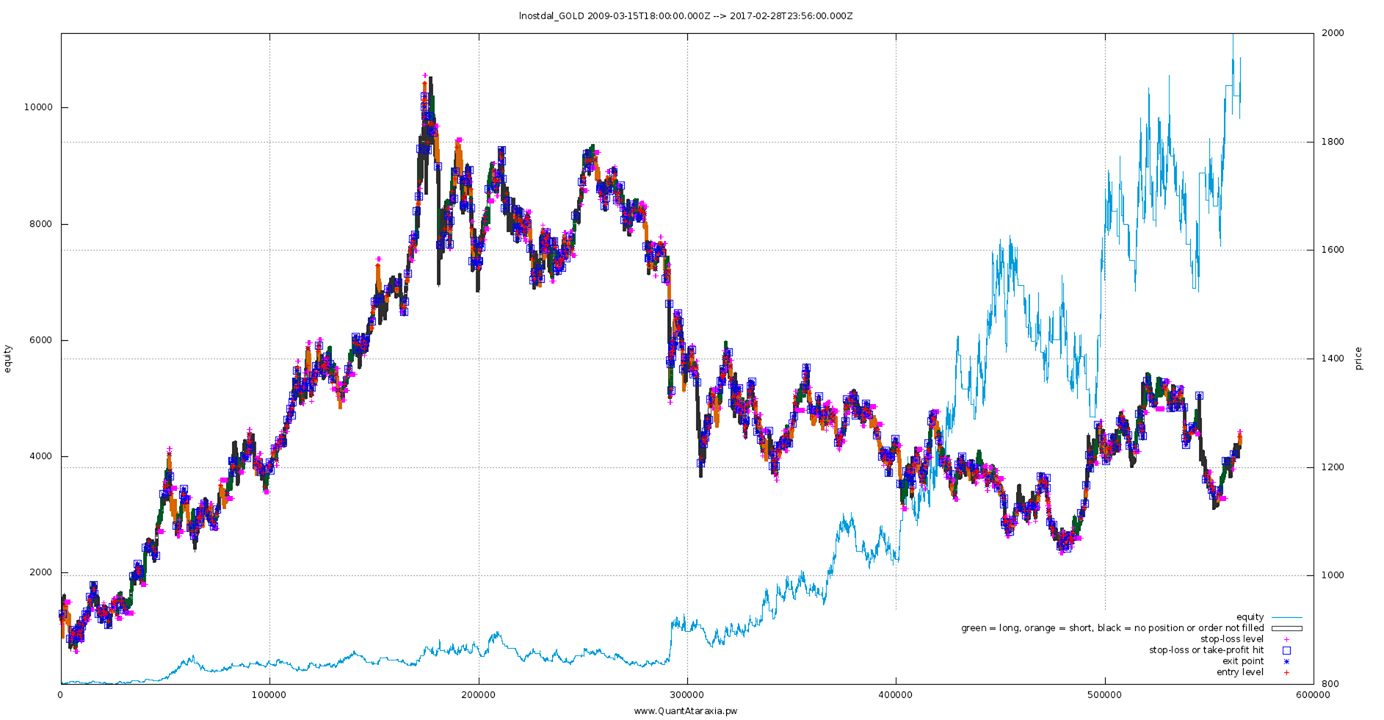

..much nicer! For some curves, log makes eyeballing things like the momentum of your returns much easier which might give you hints about a possible curve fit problem or similar – so this is not simply about aesthetics.
Happy weekend and trading!
Using a circular buffer to deal with slow exchange APIs
Using something like com.google.common.collect.EvictingQueue and only requesting the missing "tail" of your historical price data is much quicker for many broker APIs. This will help for brokers that sometimes return stale data and only supports polling i.e. you'd only poll for a limited amount of data.
In Clojure this would go something like this:
In Clojure this would go something like this:
Thursday, March 9, 2017
Quick notes on double numeric type vs. integers
NOTE: If you're dealing with "money values" you should probably do things quite differently from what I'm talking about here -- but it all depends.
Benefits of using double (primitives) instead of longs (integers) as I see it for my use case i.e. number crunching in finance and statistics:
Benefits of using double (primitives) instead of longs (integers) as I see it for my use case i.e. number crunching in finance and statistics:
- "Everything is the same". No need to constantly convert and cast back and forth between numeric types when doing e.g. division, sqrt and so on.
- Things like NaN and Infinite (vs. Finite; testable) turns out to be really useful. E.g. NaN and Infinity will flow through your code and all future calculations without causing trouble and in the end your output will be NaN or Infinity. No need to check for and handle special cases all over the place – instead only doing this at the original input end; i.e. in one or just a few places.
- Dividing by 0.0 does not lead to an exception which will disrupt the flow of my program. I will get Infinite as a normal return value instead.
- Primitive doubles seem to be fast enough(?) and certainly accurate enough (I'm not dealing with money directly; only statistics which *in turn* will deal with money as integer type). GPUs also seem to have better and better support for the double primitive type so I don't feel I'm painting myself into a corner here.
- Bonus: things like Double/POSITIVE_INFINITY, Double/NEGATIVE_INFINITY, Double/MAX_VALUE, Double/MIN_VALUE and so on can or might be used to denote special information or flags.
..I'm not sure how much I might be losing with regards to performance by using doubles instead of integers – if anything at all, but for convenience and simplicity it seems very good.
Subscribe to:
Posts (Atom)